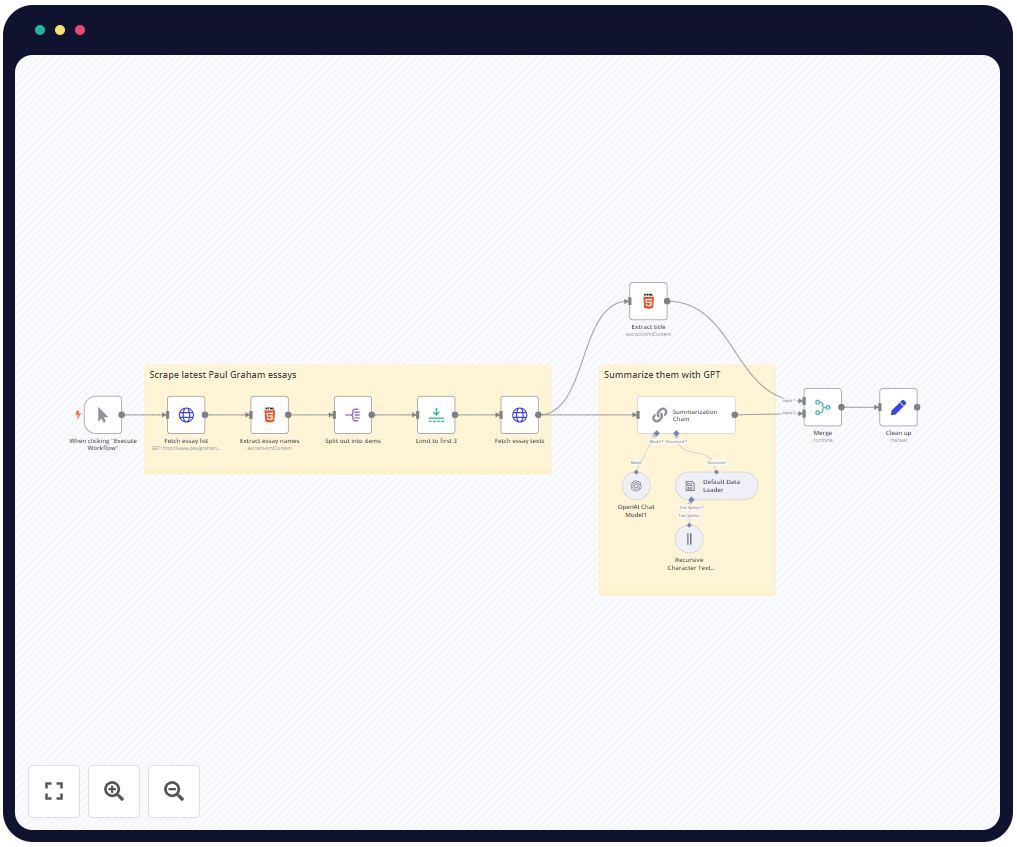
Introducción al Workflow
Scrape and summarize webpages with AI
Propósito del Workflow:
Este workflow de n8n está diseñado para automatizar el proceso de extracción y resumen de contenidos web, específicamente de ensayos publicados en el sitio web de Paul Graham. Utilizando técnicas de web scraping y modelos de lenguaje de OpenAI, el workflow recopila el contenido de los ensayos, extrae su título, y genera un resumen conciso. Esto es especialmente útil para quienes necesitan procesar y entender grandes cantidades de texto en línea de manera rápida y eficiente.
Contexto de uso:
Este workflow se puede utilizar en escenarios donde se necesita extraer y resumir información de páginas web para su análisis o revisión rápida. Es ideal para investigadores, estudiantes o profesionales que deseen obtener resúmenes de textos extensos sin necesidad de leerlos por completo. Además, se puede adaptar para extraer y procesar contenidos de otros sitios web, lo que lo convierte en una herramienta versátil para la gestión y análisis de información en línea.
Descomposición Técnica
Análisis de los Nodos
- When clicking «Execute Workflow» (Disparador Manual):
- Función: Este nodo actúa como el disparador manual del workflow. Cuando el usuario hace clic en «Ejecutar Workflow», este nodo inicia el proceso.
- Configuración: No tiene configuraciones adicionales; simplemente se utiliza para arrancar el flujo manualmente.
- Interacción: Inicia el workflow y pasa el control al siguiente nodo, que es «Fetch essay list».
- Fetch essay list (Obtener lista de ensayos):
- Función: Realiza una solicitud HTTP al sitio web de Paul Graham para obtener la lista de ensayos disponibles.
- Configuración: Configurado para hacer una solicitud GET a la URL específica que contiene la lista de ensayos (http://www.paulgraham.com/articles.html).
- Interacción: Recibe la página HTML y la pasa al siguiente nodo para extraer la lista de ensayos.
- Extract essay names (Extraer nombres de los ensayos):
- Función: Extrae los enlaces a los ensayos de la página HTML obtenida en el paso anterior.
- Configuración: Utiliza un selector CSS (
table table a) para capturar los atributoshrefde los enlaces a los ensayos. - Interacción: Los enlaces extraídos se pasan al nodo «Split out into items» para ser procesados individualmente.
- Split out into items (Dividir en elementos):
- Función: Divide la lista de enlaces de ensayos en elementos individuales para su procesamiento.
- Configuración: Está configurado para dividir la lista de ensayos en elementos individuales.
- Interacción: Pasa cada enlace individual al nodo «Limit to first 3».
- Limit to first 3 (Limitar a los primeros 3):
- Función: Limita el número de ensayos a procesar a los primeros tres.
- Configuración: Configurado para procesar solo los primeros tres ensayos de la lista.
- Interacción: Pasa los enlaces de los tres primeros ensayos al nodo «Fetch essay texts».
- Fetch essay texts (Obtener textos de ensayos):
- Función: Realiza solicitudes HTTP para obtener el contenido completo de cada ensayo utilizando los enlaces extraídos.
- Configuración: Hace una solicitud GET para cada URL de ensayo.
- Interacción: Pasa el contenido HTML del ensayo a los nodos «Extract title» y «Summarization Chain».
- Extract title (Extraer título):
- Función: Extrae el título del ensayo del contenido HTML.
- Configuración: Utiliza el selector CSS
titlepara capturar el título del documento. - Interacción: Pasa el título extraído al nodo «Merge».
- Summarization Chain (Cadena de resumen):
- Función: Usa un modelo de OpenAI para generar un resumen del contenido del ensayo.
- Configuración: Configurado para operar en modo «documentLoader», lo que permite resumir el contenido utilizando el modelo GPT-4o-mini.
- Interacción: Pasa el resumen generado al nodo «Merge».
- Merge (Combinar):
- Función: Combina el título y el resumen del ensayo en un solo objeto JSON.
- Configuración: Combina los datos por posición, asegurando que el título y el resumen correspondan al mismo ensayo.
- Interacción: Pasa el resultado combinado al nodo «Clean up».
- Clean up (Limpiar):
- Función: Formatea los datos finales, incluyendo el título, el resumen y la URL del ensayo.
- Configuración: Configurado para estructurar el objeto JSON final con el título, el resumen y la URL.
- Interacción: Este nodo produce la salida final, que puede ser utilizada para almacenamiento, presentación o análisis adicional.
Explicación del Flujo
- El workflow se inicia manualmente a través del nodo «When clicking ‘Execute Workflow’».
- A continuación, el nodo «Fetch essay list» realiza una solicitud HTTP para obtener la lista de ensayos desde el sitio web de Paul Graham.
- El nodo «Extract essay names» extrae los enlaces a los ensayos desde el HTML recibido.
- Luego, el nodo «Split out into items» divide la lista de ensayos en elementos individuales.
- «Limit to first 3» selecciona los primeros tres ensayos para ser procesados.
- El nodo «Fetch essay texts» recupera el contenido completo de los ensayos seleccionados.
- El contenido se envía a «Extract title» para extraer el título y a «Summarization Chain» para generar un resumen.
- Los resultados se combinan en el nodo «Merge».
- Finalmente, el nodo «Clean up» formatea los datos y produce la salida final, con el título, resumen y URL de cada ensayo.
JSON y Código
JSON del Workflow
A continuación, se presenta el JSON del workflow que hemos estado analizando. Voy a desglosar los elementos más relevantes y explicar cómo cada configuración afecta el comportamiento del workflow.
{
"meta": {
"instanceId": "408f9fb9940c3cb18ffdef0e0150fe342d6e655c3a9fac21f0f644e8bedabcd9"
},
"nodes": [
{
"id": "67850bd7-f9f4-4d5b-8c9e-bd1451247ba6",
"name": "When clicking \"Execute Workflow\"",
"type": "n8n-nodes-base.manualTrigger",
"position": [
-740,
1000
],
"parameters": {},
"typeVersion": 1
},
{
"id": "0d9133f9-b6d3-4101-95c6-3cd24cdb70c3",
"name": "Fetch essay list",
"type": "n8n-nodes-base.httpRequest",
"position": [
-520,
1000
],
"parameters": {
"url": "http://www.paulgraham.com/articles.html",
"options": {}
},
"typeVersion": 4.1
},
{
"id": "ee634297-a456-4f70-a995-55b02950571e",
"name": "Extract essay names",
"type": "n8n-nodes-base.html",
"position": [
-300,
1000
],
"parameters": {
"options": {},
"operation": "extractHtmlContent",
"dataPropertyName": "=data",
"extractionValues": {
"values": [
{
"key": "essay",
"attribute": "href",
"cssSelector": "table table a",
"returnArray": true,
"returnValue": "attribute"
}
]
}
},
"typeVersion": 1
},
{
"id": "83d75693-dbb8-44c4-8533-da06f611c59c",
"name": "Fetch essay texts",
"type": "n8n-nodes-base.httpRequest",
"position": [
360,
1000
],
"parameters": {
"url": "=http://www.paulgraham.com/{{ $json.essay }}",
"options": {}
},
"typeVersion": 4.1
},
{
"id": "151022b5-8570-4176-bf3f-137f27ac7036",
"name": "Extract title",
"type": "n8n-nodes-base.html",
"position": [
700,
700
],
"parameters": {
"options": {},
"operation": "extractHtmlContent",
"extractionValues": {
"values": [
{
"key": "title",
"cssSelector": "title"
}
]
}
},
"typeVersion": 1
},
{
"id": "07bcf095-3c4d-4a72-9bcb-341411750ff5",
"name": "Clean up",
"type": "n8n-nodes-base.set",
"position": [
1360,
980
],
"parameters": {
"fields": {
"values": [
{
"name": "title",
"stringValue": "={{ $json.title }}"
},
{
"name": "summary",
"stringValue": "={{ $json.response.text }}"
},
{
"name": "url",
"stringValue": "=http://www.paulgraham.com/{{ $('Limit to first 3').item.json.essay }}"
}
]
},
"include": "none",
"options": {}
},
"typeVersion": 3
},
{
"id": "cda47bb7-36c5-4d15-a1ef-0c66b1194825",
"name": "Merge",
"type": "n8n-nodes-base.merge",
"position": [
1160,
980
],
"parameters": {
"mode": "combine",
"options": {},
"combineBy": "combineByPosition"
},
"typeVersion": 3
},
{
"id": "28144e4c-e425-428d-b3d1-f563bfd4e5b3",
"name": "Summarization Chain",
"type": "@n8n/n8n-nodes-langchain.chainSummarization",
"position": [
720,
1000
],
"parameters": {
"options": {},
"operationMode": "documentLoader"
},
"typeVersion": 2
},
{
"id": "022cc091-9b4c-45c2-bc8e-4037ec2d0d60",
"name": "OpenAI Chat Model1",
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"position": [
680,
1200
],
"parameters": {
"model": "gpt-4o-mini",
"options": {}
},
"credentials": {
"openAiApi": {
"id": "8gccIjcuf3gvaoEr",
"name": "OpenAi account"
}
},
"typeVersion": 1
}
],
"connections": {
"Merge": {
"main": [
[
{
"node": "Clean up",
"type": "main",
"index": 0
}
]
]
},
"Extract title": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 0
}
]
}
},
"Fetch essay list": {
"main": [
[
{
"node": "Extract essay names",
"type": "main",
"index": 0
}
]
}
},
"Limit to first 3": {
"main": [
[
{
"node": "Fetch essay texts",
"type": "main",
"index": 0
}
]
}
},
"Fetch essay texts": {
"main": [
[
{
"node": "Extract title",
"type": "main",
"index": 0
},
{
"node": "Summarization Chain",
"type": "main",
"index": 0
}
]
}
},
"OpenAI Chat Model1": {
"ai_languageModel": [
[
{
"node": "Summarization Chain",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Extract essay names": {
"main": [
[
{
"node": "Split out into items",
"type": "main",
"index": 0
}
]
}
},
"Summarization Chain": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 1
}
]
}
}
}
}
Estructura del JSON:
meta: Contiene información meta sobre la instancia de n8n.nodes: Es una lista de nodos que participan en el workflow, donde cada nodo tiene unid,name,type,position,parameters,credentials, ytypeVersion.connections: Define cómo los nodos están conectados entre sí. Las conexiones determinan el flujo de datos y cómo se pasa la información de un nodo a otro.
Componentes Específicos:
- Solicitud HTTP (
Fetch essay listyFetch essay texts): Estos nodos son clave para obtener la lista de ensayos y el contenido de cada ensayo. Configurados con URLs específicas, extraen la información necesaria para su procesamiento posterior. - Extracción HTML (
Extract essay namesyExtract title): Estos nodos utilizan selectores CSS para extraer enlaces y títulos del contenido HTML. Son cruciales para identificar y procesar los datos relevantes del contenido web. - Modelo de Lenguaje (
OpenAI Chat Model1): Este nodo utiliza el modelo GPT-4o-mini de OpenAI para generar resúmenes de los ensayos. Está conectado directamente al nodo de resumen, aportando la capacidad de generar texto de manera coherente y concisa. - Combinación y Formateo (
MergeyClean up): Estos nodos son responsables de combinar los datos extraídos (título, resumen, URL) y formatearlos en una estructura JSON final adecuada para su uso posterior.
Código Personalizado
En este workflow no se incluyen nodos con código personalizado en el JSON proporcionado. Sin embargo, la lógica de procesamiento está configurada mediante la selección de nodos y la definición de parámetros específicos que guían el comportamiento del workflow.
Posibles Mejoras y Adaptaciones
Optimización
- Mejoras en la Eficiencia del Web Scraping:
- Manejo de Tiempos de Espera y Retries: Se podría configurar el nodo de solicitudes HTTP para manejar mejor los tiempos de espera y los reintentos en caso de fallos en la red o en la respuesta del servidor, lo que mejoraría la estabilidad del workflow.
- Optimización de la Extracción de Datos: La extracción de datos mediante selectores CSS podría optimizarse especificando selectores más precisos o añadiendo condiciones adicionales para evitar capturar datos no deseados.
- Reducción del Costo de API:
- Limitación de Resúmenes: Para reducir el costo asociado al uso del modelo de lenguaje, se podría implementar un nodo de decisión que determine si es necesario resumir todos los ensayos o si es suficiente con un subconjunto.
- Uso de Modelos Alternativos: Considerar el uso de un modelo de lenguaje menos costoso para ensayos que no requieren un análisis profundo o un resumen detallado, optimizando así los recursos utilizados.
- Mejora en la Calidad de los Resúmenes:
- Preprocesamiento del Texto: Añadir un nodo que realice un preprocesamiento del texto antes de enviarlo al modelo de lenguaje para eliminar contenido irrelevante o ruidoso, mejorando la calidad del resumen generado.
- Personalización del Modelo: Ajustar los parámetros del modelo de lenguaje para que se enfoque en aspectos específicos del texto, como ideas clave o temas recurrentes, lo que podría generar resúmenes más útiles y precisos.
Escalabilidad
- Manejo de un Mayor Volumen de Ensayos:
- División en Lotes: Implementar una lógica que divida la lista de ensayos en lotes manejables para evitar sobrecargar el sistema y permitir que el workflow procese grandes volúmenes de datos de manera más eficiente.
- Paralelización de Tareas: Configurar nodos que permitan el procesamiento paralelo de ensayos para acelerar el tiempo total de ejecución del workflow, lo que sería especialmente útil cuando se trata de un gran número de ensayos.
- Integración con Sistemas Externos:
- Almacenamiento en Base de Datos: Ampliar el workflow para que los resúmenes generados se almacenen directamente en una base de datos, facilitando la posterior consulta y análisis.
- Automatización Continua: Integrar el workflow con un sistema de monitorización de cambios en el sitio web, de manera que cada vez que se publique un nuevo ensayo, el workflow se ejecute automáticamente para generar el resumen.
Variantes del Workflow
- Resumen de Artículos de Noticias:
- Este workflow podría adaptarse para realizar scraping y resumen de artículos de noticias de diferentes fuentes, configurando los nodos para manejar múltiples sitios web y tipos de contenido.
- Monitoreo de Blogs:
- Podría modificarse para monitorear blogs de interés y generar resúmenes periódicos de las nuevas entradas, ofreciendo a los usuarios un boletín automatizado con los resúmenes de los últimos posts.
- Agregador de Contenidos:
- Una variante interesante sería utilizar este workflow como parte de un agregador de contenidos, donde se recopilen y resuman publicaciones de múltiples fuentes para ofrecer a los usuarios una vista consolidada de temas específicos.
Conclusiones y Aplicaciones Prácticas
Este workflow de n8n es una herramienta potente para la automatización de tareas que requieren la extracción y resumen de contenidos web. Su capacidad para manejar de manera eficiente el scraping de páginas web y la generación de resúmenes mediante un modelo de lenguaje de OpenAI lo hace ideal para profesionales que necesitan procesar grandes volúmenes de información en línea de manera rápida y concisa.
Las aplicaciones prácticas de este workflow son diversas. Puede ser utilizado por investigadores, periodistas, y estudiantes que necesiten resumir artículos, ensayos, o publicaciones de blogs de manera sistemática. También es útil para empresas que buscan automatizar la monitorización de contenido en la web, generando resúmenes que pueden ser almacenados o distribuidos a través de informes automatizados.
Te invito a probar este workflow en tus propios proyectos para experimentar su eficiencia en la extracción y resumen de contenidos web. Además, considera las posibles adaptaciones y mejoras para ajustarlo aún más a tus necesidades específicas. No dudes en compartir tus experiencias o en solicitar asistencia para optimizar este workflow en diferentes contextos.
Deja un comentario